All code can be accessed here:
https://github.com/sspusapaty/accenttransfer
Introduction
Have you ever wondered how you would sound like if you grew up in another country. say India or Great Britain? Obviously your accent would change, but the natural tones of your voice would remain consistent.
The purpose of this project was to see if we could use deep learning to be able to convert a speaker's accent from one region to another while maintaining their voice's inherent characteristics.

The idea of style transfer in the realm of audio hasn't been explored as much as images, especially when it comes to accents. Due to the challenging nature of this task, we were excited to pursue it.
Background
We found a paper from Stanford that attempted to create matrix transformations for the American accent to Indian and Scottish accents ("Accent Conversion Using Artificial Neural Networks", Bearman). In the paper their input data as well as labels came from a single speaker. We were concerned with this as we wanted to create transformations for any voice. The paper reported a low error while also admitting that the final audio was noisy due to the loss of converting data back into audio. We believed that the lower cost can be attributed to overfitting due to a massive number of epochs (5000) and the fact that the dataset came from a different speaker. Rather than trying to show the cost as measure of accuracy, we wanted our output to maximize quality and human consistency.
Data Sources
Our data came from two direct sources. One was a Kaggle dataset of about ~2000 speakers of various regions all saying the same 69-word paragraph. This was useful for standardization. Another source of data came from a website called Forvo. This website crowdsources many pronunciations for a single word. With the website's API we were able to make about 500 calls a day to gather these various pronunciations. The data from Forvo was useful because there was a much larger variety of spoken words, but much fewer speakers per word. All audio samples came as mp3 files.
Data Pre-processing
Isolating words: We decided that, instead of training on entire phrases (albeit frames of these phrases), we wanted our model to train on a specific word. To do this, we needed to cut our Kaggle dataset from a paragraph of audio to individual words. To do this, we used the IBM Watson API to identify the time frames of keywords within the audio file, then cut the audio file into many chunks at each time frame (one for each word).

Extracting features: The most immediate problem at first was to consider how to extract features from large audio files. A common way we saw in literature for accent classifiers was to extract a series of numbers from the audio sample called mel frequency cepstral coefficients (MFCC). MFCCs are based off the mel scale, which is designed to correlate to the human auditory response system. Because of this, we determined that MFCCs likely contained information regarding accents. We decided to extract 25 MFCCs for each 5ms framerate. We implemented this using the feature.mfcc function in the Librosa Python library.
The problem is, the process from audio to MFCCs is invertible. In other words, it is straightforward to convert audio to MFCCs, but converting MFCCs back into audio is very lossy. This introduces a LOT of noise into the output. This is a problem that we struggled with throughout the project. We implemented this inverse MFCC method that uses random excitation to recreate lost data.
Aligning speech: Another potential bias could occur through the fact that different speakers speak at different rates. In order to "align" the MFCCs for each speaker, we employ Fast Dynamic Time Warping. An O(N)-on-average algorithm that does this. Essentially, this algorithm stretches or compresses different parts of each sample such that the "distance" between them is minimized:
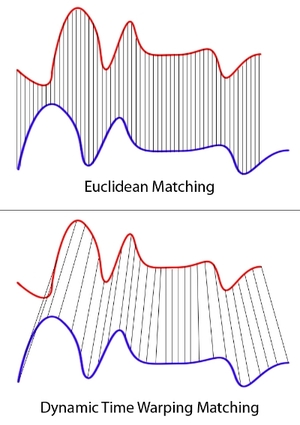
*Image from wikipedia
The Model and Training
Although we began trying to train a model on a large sample of English words, we eventually decided to build a model to convert a single word -- "brother". The input is a set of MFCC coefficients in a 5ms frame, surrounded by around 30 frames of context. The target output is three frames of 5 millisecond MFCC coefficients of the target accent. Context is important because phonemes in an accent depend heavily on neighboring phonemes. We aimed to convert from an American accent to a British accent. We had about 200 speakers for each accent. To "multiply" the data, we did a Cartesian product between input data and output data, producing each possible pair of speakers. Thus we had 40,000 samples of data, which we had to reduce to about 10,000 samples to deal with data transfer issues between local computer and cluster.
First, to initialize weights that reasonably output well-formed speech, we pre-trained a model where the input and output were identical (the same speech sample). By doing this, the normal training is more efficient because it an train on linguistic features rather than figuring out trivial things such as silence or speech characteristics.

The simple fully-connected model architecture above was used for both pre-training and training models. The dimension of the input is is 1 X 1575 (63*25) and the output layer has a dimension of 1 X 75 (3*25). There are two hidden layers of 100 nodes each and both use the tanh activation function.

The model was trained with a starting learning rate of 0.0001 and with Adam's Optimizer. The cost function was mean-squared error. The pretraining model was trained with 500 epochs and the normal model was trained with 1000 epochs.
Post-Processing
The obvious problem is that by training frame by frame, we get a choppy audio output. In order to "smoothen" the final audio, we output a set of 3 5ms frames, with a stride of 1ms, and average the overlapping frames as shown in the image below:

Converting the MFCCs back into audio involved building our own function that reversed the steps of audio-to-MFCC. By playing around with the parameters of the function, we were able to make our reversal as lossless as possible (still very lossy though).
Pitfalls
As expected there were many pitfalls.
The most immediate issue was that the Stanford paper we based our initial assumptions on did not produce quality audio as output despite overfitting to a low loss. This made us quite uneasy about maintaining the human sound no matter our loss.
This expectation was worsened when we had to deal with the lossy MFCC reconstruction that we made before. We tried looking at invertible values like LPC's, but in the end, we decided that "accents" would most likely be contained in MFCCs.
A large part of the challenge came with the actual creation and movement of data. Cutting up large audio files into smaller ones was a several-hour process. Extracting the MFCCs and building the data tables for 40,000 pairs took 8 hrs on our CPU (We could not use the GPU cluster provided to us due to library inconsistencies). Training the model was also a very timely process. Thus the overall procedure limited the amount of testing a training we could do.
Results
Our pretraining model achieved a mean-squared error of ~61. The output sounds human and the word is actually maintained (albeit lot of noise). The actual model achieved a mean-squared error of ~200. The output maintains syllables, but the content is lost due to noise. Audio files can be reached here:
https://github.com/sspusapaty/accenttransfer
Future Work and Reflections
It's immediately obvious to us that the waveform reconstruction from MFCCs to audio needs some work. Fortunately, there is some research on using GANS to do this.
It also would be interesting to test our model's output on an accent classifier to see if our output is an adversarial example or if the "accent" has already been reached.
It would also be useful to see which accents have the best conversion qualities once the above properties are improved.
Applications
- Helpful to understand thick accents
- Can be used to present information in a more familiar way given location
- Can possibly be used for speech training (by understanding personal difference in voice to target accent)